
[ 프롤로그 ]
회사에서 쿠버네티스를 도입한 지 얼마 되지 않았다.
쿠버네티스 모니터링 시스템을 구축하라는 명을 받고
- Fluentd(로그 수집 도구)
- ElasticSearch (로그 저장 및 검색)
- Kibana (수집된 로그를 시각화)
이 3가지를 연결한 내용을 정리하였다.
[ 상황 ]
(1) 모니터링 시스템을 구축하기 위해
ElasticSearch와 Kibana를 만들었다.
참고로 ElasticSearch는 VM 환경에 배포하였다.
이유는 안정화를 높이기 위해
모니터링 시스템은 쿠버네티스 노드와 격리된 환경에서 구축하는 것이 좋다고 생각했기 때문이다.
(2) 로그 수집을 담당하는 Fluentd는
Kubernetes DaemonSet을 이용하여
각 노드에 설치하였다.
(3) Fluentd를 선택한 이유
Fluentd는 Kubernetes DaemonSet으로 쉽게 배포할 수 있고
다양한 플러그인을 통한 확장성과 유연성이 뛰어나기 때문에
여러 로그 소스를 손쉽게 통합하여 Elasticsearch로 보내기 위한 용도로 적합하다고 판단하였다.
(4) Elasticsearch를 선택한 이유
Elasticsearch는 대용량의 로그 데이터를 효율적으로 저장하고
실시간 검색 및 분석 기능을 제공하기 때문에 선택했다.
Kibana와의 연계로 수집된 로그를 시각화하여 문제를 빠르게 파악할 수 있는 장점이 있다.
(5) Kibana를 선택한 이유
Kibana는 Elasticsearch에 저장된 데이터를
시각화하고 실시간으로 모니터링할 수 있는 대시보드 기능을 제공하기 때문에 선택했다,
결론적으로 말하면
나는 Fluentd와 ElasticSearch Kibana를 연결하기 위해
아래와 같이 4가지 설정 파일을 만들었다.
(1) fluentd-elasticsearch-daemonset.yaml
(2) fluentd-monitoring-role.yaml
(3) fluentd-monitoring-role-binding.yaml
(4) fluentd-configmap.yaml
아래에서 하나하나 왜 필요한지 살펴보고자 한다.
(1) fluentd-elasticsearch-daemonset.yaml
먼저 이 설정파일은
쿠버네티스의 각 노드에 Fluentd를 설치하여
로그를 수집하고
Elasticsearch로 전송하기 위한 내용을 담고 있다.
아래는 설정파일 예시이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: saida
labels:
k8s-app: fluentd-logging
version: v1
spec:
selector:
matchLabels:
k8s-app: fluentd-logging
version: v1
template:
metadata:
labels:
k8s-app: fluentd-logging
version: v1
spec:
serviceAccountName: fluentd-service-account # 권한
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearch
env:
- name: K8S_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# Elasticsearch 호스트 및 포트
- name: FLUENT_ELASTICSEARCH_HOST
value: "0.0.0.0" # 각 상황에 맞게 조정 필요
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200" # 각 상황에 맞게 조정 필요
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
# Elasticsearch 플러그인 설정
- name: FLUENT_ELASTICSEARCH_SSL_VERIFY
value: "false"
- name: FLUENT_ELASTICSEARCH_SSL_VERSION
value: "TLSv1_2"
# X-Pack Authentication 또는 기타 인증 설정
- name: FLUENT_ELASTICSEARCH_USER
value: "elastic"
- name: FLUENT_ELASTICSEARCH_PASSWORD
value: "password" # 각 상황에 맞게 조정 필요
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: dockercontainerlogdirectory
mountPath: /var/log/pods
readOnly: true
# Fluentd 설정 파일을 추가하는 부분
- name: fluentd-config-volume
mountPath: /fluentd/etc
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: dockercontainerlogdirectory
hostPath:
path: /var/log/pods
# Fluentd 설정 파일을 저장할 ConfigMap 을 지정하는 부분
- name: fluentd-config-volume
configMap:
name: fluentd-config
|
cs |
[ 설정 파일 요약 ]
배포 방식
DaemonSet으로 구성되어 Kubernetes 클러스터의 모든 노드에 Fluentd Pod가 하나씩 배포된다.
각 노드에서 생성된 로그(예: /var/log 디렉토리)를 수집하는 데 적합하다.
로그 전송 대상
Fluentd는 수집한 로그를 Elasticsearch로 전송한다.
FLUENT_ELASTICSEARCH_HOST, FLUENT_ELASTICSEARCH_PORT로 전송 대상 호스트와 포트를 지정한다.
Fluentd 이미지
fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearch 이미지를 사용하여 Elasticsearch 플러그인과 연동되도록 설정한다.
자원 제한
Fluentd의 자원 사용량을 limits로 제한하여 노드에서 과도한 CPU나 메모리 사용을 방지한다.
권한 및 인증
serviceAccountName과 tolerations를 통해 Fluentd가 Control Plane 노드에도 배포될 수 있도록 구성한다.
Elasticsearch 사용자 이름과 비밀번호(FLUENT_ELASTICSEARCH_USER, FLUENT_ELASTICSEARCH_PASSWORD)를 설정하여 인증한다.
버퍼링 및 안정성
Fluentd는 Elasticsearch에 전송 중 실패할 경우 버퍼링 기능(디스크 또는 메모리 저장)을 기본적으로 지원한다.
fluentd-config-volume으로 설정 파일을 ConfigMap에서 가져와 세부 플러그인 설정을 관리한다.
(2) fluentd-monitoring-role.yaml
그다음은
Kubernetes에서 Fluentd가 수행할 수 있는 작업에 대한 권한을 설정하는 역할(role)을 정하는 파일이다.
이 파일은 Kubernetes에서 롤-베이스 액세스 제어(RBAC)를 사용하여
Fluentd가 클러스터 내의 모니터링 관련 리소스에 접근할 수 있도록 하는 것이다.
|
1
2
3
4
5
6
7
8
|
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd-monitoring-role
rules:
- apiGroups: [""]
resources: ["namespaces", "pods", "services"] # 상황에 맞게 조정 필요
verbs: ["get", "list", "watch"] # 상황에 맞게 조정 필요
|
cs |
(3) fluentd-monitoring-role-binding.yaml
이 파일은
Kubernetes 클러스터에서 Fluentd가 사용할 서비스 계정에
권한을 부여하기 위한 역할 바인딩을 설정하는 곳이다.
Fluentd가 my-service-namespace 라는 네임 스페이스에 있는
fluentd-service-account 서비스 계정을 사용하여
모니터링 관련 리소스에 액세스할 수 있도록 권한을 부여하는 역할을 한다.
이때 namesapce는 각 상황에 맞게 수정해 주어야 하는 부분이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluentd-monitoring-role-binding
subjects:
- kind: ServiceAccount
name: fluentd-service-account
namespace: my-service-namespace # 상황에 맞게 조정 필요
roleRef:
kind: ClusterRole
name: fluentd-monitoring-role
apiGroup: rbac.authorization.k8s.io
|
cs |
참고로 처음부터 이 파일이 필요한지는 알지 못했다.
그런데 fluentd pod 상태가 CrashLoopBackOff여서
로그를 살펴보니 아래와 같은 부분이 있었다
pods is forbidden: User \"system:serviceaccount:kube-system:default\" cannot list resource
오류의 내용을 살펴보면 Fluentd가 Kubernetes API 서버에 연결하여
Pod들의 정보를 가져오려고 시도했으나
권한이 없어서 실패했다는 것이다.
구체적으로는 "system:serviceaccount:kube-system:default" 사용자가
클러스터 범위에서 API 그룹내의 "pods" 리소스를 나열할 수 없다는 것이다.
이를 해결하기 위해 RBAC (Role-Based Access Control) 설정을 추가해야 한다.
여기서는 fluentd를 실행하는 ServiceAccount인 fluentd-service-account에게
적절한 권한을 부여하는 ClusterRole과 ClusterRoleBinding을 정의해야 한다.
이러한 설정을 추가하면 fluentd가 Kubernetes API에 연결하여 필요한 정보를 가져올 수 있다.
그래서 원래는 fluentd-monitoring-role.yaml 파일만 있었는데
위 에러를 해결하기 위해 이 바인딩 파일도 추가가 되었다.
그리고 아래 내용이 권한 설정보다 선행되어야 한다.
Kubernetes 시스템 네임스페이스에서의 이벤트를 확인하기 위해 아래 명령어를 활용할 수 있다.
kubectl get events
그런데 아래와 같은 내용으로 에러가 났었다.
"fluentd-" is forbidden: error looking up service account kube-system/fluentd-service-account:
serviceaccount "fluentd-service-account" not found
fluentd의 DaemonSet에서 지정한
서비스 계정(fluentd-service-account)이 존재하지 않음을 의미하는 것이다.
네임스페이스 fluentd-service-account 서비스 계정이 있는지 확인한 후
없으면 아래 명령어로 생성해 주면된다.
kubectl create serviceaccount fluentd-service-account -n <namespace>
kubectl rollout restart daemonset fluentd -n <namespace>
(4) fluentd-configmap.yaml
이 파일은 Fluentd가 어떤 로그를 어떻게 수집하고 전송할지에 대한 구체적인 설정을 정의한다.
이 파일에서 정말 삽질을 많이 했다.
나는 아래와 같이 최종 설정파일을 완성했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluent.conf: |
<source>
@type tail
@id in_tail_pods_logs
path "/var/log/containers/saida*.log"
pos_file "/var/log/fluentd-containers.log.pos"
tag "kubernetes.*"
exclude_path ["/var/log/pods/fluent*"]
read_from_head true
<parse>
@type multiline
format_firstline /^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d+Z stdout F \[[^\]]+\]\[\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d+\]/
format1 /^(?<time>[^\s]+) (?<stream>\S+) F (?<log>.+)$/
</parse>
</source>
<filter kubernetes.var.log.containers.**>
@type parser
<parse>
@type regexp
expression /\[(?<service_name>[^\]]+)\]/
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
keep_time_key true
</parse>
replace_invalid_sequence true
emit_invalid_record_to_error false
key_name log
reserve_data true
<record>
service_name ${record["service_name"]}
</record>
</filter>
<match kubernetes.var.log.containers.*.log>
@type elasticsearch
host 0.0.0.0
port 9200
logstash_format true
logstash_dateformat %Y.%m.%d
<buffer>
@type file
path /var/log/td-agent/buffer/elasticsearch
</buffer>
<secondary>
@type secondary_file
directory /var/log/td-agent/error
basename saida_stg_logs
</secondary>
user elastic
password password
</match>
|
cs |
fluentd-configmap.yaml 은 중요해서 조금 더 자세히 보려고 한다.
먼저 이 <source> 부분은
Fluentd가 데이터를 수집하는 위치와 방법을 정의하는 곳이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<source>
@type tail
@id in_tail_pods_logs
path "/var/log/containers/my-service*.log"
pos_file "/var/log/fluentd-containers.log.pos"
tag "kubernetes.*"
exclude_path ["/var/log/pods/fluent*"]
read_from_head true
<parse>
@type multiline
format_firstline /^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d+Z stdout F \[[^\]]+\]\[\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d+\]/
format1 /^(?<time>[^\s]+) (?<stream>\S+) F (?<log>.+)$/
</parse>
</source>
|
cs |
- @type tail
데이터를 테일링(tailing)하여 실시간으로 로그 파일을 읽어오는 방식을 사용한다는 것을 나타낸다.
- @id in_tail_pods_logs
이 source 블록을 식별하는 고유한 ID
- path "/var/log/containers/my-service*.log"
로그 파일의 경로를 지정한다.
여기서는 /var/log/containers/ 디렉토리에 있는 my-service*.log 파일을 모두 수집한다는 의미다.
아래 2개 명령어를 이용해서 실제로 /var/log/container 에 로그 파일이 있는지 확인 후
각 상황에 맞게 고쳐줘야 하는 부분이다.
kubectl get pods
kubectl exec -it <pod 이름> -- /bin/bash
- pos_file "/var/log/fluentd-containers.log.pos"
파일의 현재 위치를 추적하기 위한 위치 파일의 경로를 지정한다.
이를 통해 Fluentd는 마지막으로 읽은 위치를 추적하여 중복 데이터를 방지한다.
tag "kubernetes.*"
수집된 데이터에 부여할 태그를 지정한다.
여기서는 kubernetes를 포함하는 모든 태그가 적용된다.
exclude_path ["/var/log/pods/fluent*"]
특정 경로의 파일을 제외하여 데이터를 수집한다.
여기서는 /var/log/pods/ 디렉토리에 있는 fluent* 파일을 제외한다.
read_from_head true
로그 파일을 처음부터 읽는 옵션을 활성화한다는 의미이다.
그다음 <parse> 안에 있는 부분이 중요하다.
여기서 가장 많은 삽질을 했다.
|
1
2
3
4
5
|
<parse>
@type multiline
format_firstline /^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d+Z stdout F \[[^\]]+\]\[\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d+\]/
format1 /^(?<time>[^\s]+) (?<stream>\S+) F (?<log>.+)$/
</parse>
|
cs |
format_firstline
이 정규 표현식은 다중 라인 로그에서 첫 번째 라인을 식별하기 위한 것이다.
다중 라인 로그의 첫 번째 라인을 식별하기 위한 패턴을 지정한다.
예를 들어 내 로그는 아래와 같은 형식으로 시작된다.
2024-03-28T04:20:59.651183369Z stdout F [my-service-api][2024-03-28 13:20:59.650][DEBUG][org.hibernate.SQL.logStatement:line128] -
나는 2024-03-28T04:20:59.651183369Z stdout F [my-service-api][2024-03-28 13:20:59.650]
여기를 로그의 첫 라인이라고 인식시키고 싶었기 때문에
foramt_firstline 정규식을 위와 같이 작성했다.
format1
이 정규 표현식은 각각의 라인에서 추출하고자 하는 필드를 정의하는 부분이다.
로그 라인에서 시간(time), 스트림(stream), 로그(log) 등의 필드를 추출하기 위한 패턴을 지정한다.
이때 각 필드는 이름화된 그룹으로 정의된다.
그다음은 filter 부분이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<filter kubernetes.var.log.containers.**>
@type parser
<parse>
@type regexp
expression /\[(?<service_name>[^\]]+)\]/
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
keep_time_key true
</parse>
replace_invalid_sequence true
emit_invalid_record_to_error false
key_name log
reserve_data true
<record>
service_name ${record["service_name"]}
</record>
</filter>
|
cs |
<filter kubernetes.var.log.containers.**>
이 부분은 특정 패턴을 가진 로그 라인을 필터링하는 데 사용된다.
이 경우에는 kubernetes.var.log.containers.* 패턴을 가진 로그 라인을 필터링한다.
@type parser
이 필터는 로그 라인을 파싱 하기 위해 parser 타입을 사용한다.
<parse>
이 부분은 정규 표현식을 사용하여 로그 라인을 파싱 하는 부분이다.
@type regexp
이 부분은 정규 표현식을 사용하여 로그 라인을 파싱 한다.
expression /\[(?<service_name>[^\]]+)\]/
이 부분은 정규 표현식으로,
로그 라인에서 [...] 패턴을 찾아 service_name이라는 이름의 필드로 추출한다.
time_key time
이 부분은 로그 라인에서 시간 정보를 가리키는 필드를 지정합니다.
time_format %Y-%m-%dT%H:%M:%S.%NZ
이 부분은 시간 정보의 형식을 지정한다.
keep_time_key true
이 부분은 시간 정보를 유지할 것인지 여부를 지정한다.
replace_invalid_sequence true
이 부분은 파싱 중에 발생한 잘못된 시퀀스를 대체할 것인지를 지정한다.
emit_invalid_record_to_error false
이 부분은 잘못된 레코드를 오류로 표시할 것인지를 지정한다.
key_name log
이 부분은 기록될 필드의 이름을 지정한다.
reserve_data true
이 부분은 파싱 되지 않은 데이터를 유지할 것인지 여부를 지정한다.
<record>
이 부분은 파싱 된 필드를 기록하기 위해 사용된다.
service_name ${record["service_name"]}
이 부분은 service_name 필드의 값을 기록한다.
이때 ${record["service_name"]}은 파싱 된 service_name 필드의 값을 나타낸다.
그다음은 match 부분이다.
Fluentd에서 Elasticsearch로 데이터를 전송하기 위한 설정을 담당한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<match kubernetes.var.log.containers.*.log>
@type elasticsearch
host 0.0.0.0
port 9200
logstash_format true
logstash_dateformat %Y.%m.%d
<buffer>
@type file
path /var/log/td-agent/buffer/elasticsearch
</buffer>
<secondary>
@type secondary_file
directory /var/log/td-agent/error
basename stage_logs
</secondary>
user elastic
password password
</match>
|
cs |
match
데이터가 일치하는 경우에 대한 처리를 정의한다.
여기서는 모든 Kubernetes 컨테이너 로그에 대해 Elasticsearch로 전송하도록 설정되어 있다.
@type elasticsearch
데이터를 Elasticsearch로 전송하기 위한 플러그인을 지정한다.
host
Elasticsearch 호스트의 IP 주소를 지정한다.
port
Elasticsearch의 포트 번호를 지정한다.
logstash_format
데이터를 Logstash 형식으로 전송할지 여부를 지정한다.
logstash_dateformat
Logstash 형식으로 전송할 경우 날짜 포맷을 지정한다.
buffer
데이터를 임시로 저장하는 버퍼를 설정한다.
여기서는 파일 시스템을 사용하여 데이터를 버퍼링 하도록 설정되어 있다.
secondary
주요 파일 외에도 데이터의 백업을 저장하기 위한 설정을 지정한다.
여기서는 파일 시스템을 사용하여 데이터를 저장한다.
user
Elasticsearch에 연결할 때 사용할 사용자 이름을 저장한다.
password
Elasticsearch에 연결할 때 사용할 비밀번호를 저장한다.
그다음 위 설정파일을 적용하는 명령어는 다음과 같다.
예를 들어
D:\project\ 이 부분은 실제 내가 가지고 있는 파일의 경로를 적어주어야 한다.
kubectl apply -f D:\project\fluentd-monitoring-role.yaml
kubectl apply -f D:\project\fluentd-monitoring-role-binding.yaml
kubectl apply -f D:\project\fluentd-configmap.yaml
kubectl apply -f D:\project\fluentd-elasticsearch-daemonset.yaml
그리고 설정파일을 제거하는 명령어는 다음과 같다.
kubectl delete -f D:\project\fluentd-monitoring-role.yaml
kubectl delete -f D:\project\fluentd-monitoring-role-binding.yaml
kubectl delete -f D:\project\fluentd-configmap.yaml
kubectl delete daemonset fluentd -n <namespace>
그리고 아래 명령어로 플루언티디의 상태를 파악했다.
kubectl get pods
kubectl logs <fluentd-pod-name>
kubectl exec -it <fluentd-pod-name> -- /bin/bash
여기까지 내가 실제로 구축을 진행했던
Fluentd와 ElasticSearch 연결 상세 내용이다.
위와 같이 설정을 해주고
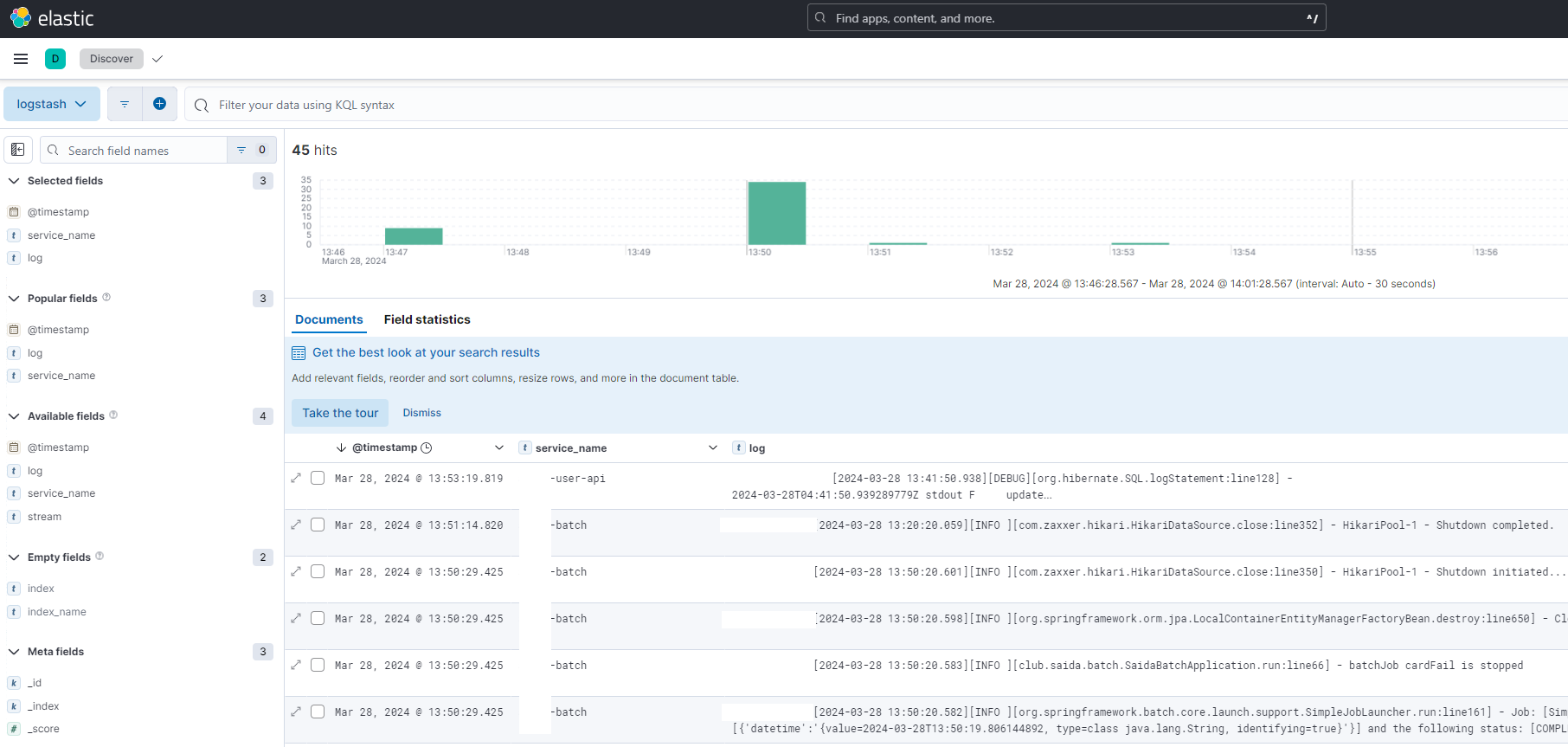
Kibana에 들어가 보면 아래와 같이 로그가 쌓이는 것을 볼 수 있다.
여러 service로 쪼개져 있기 때문에
service_name으로 구분을 하기로 했다.
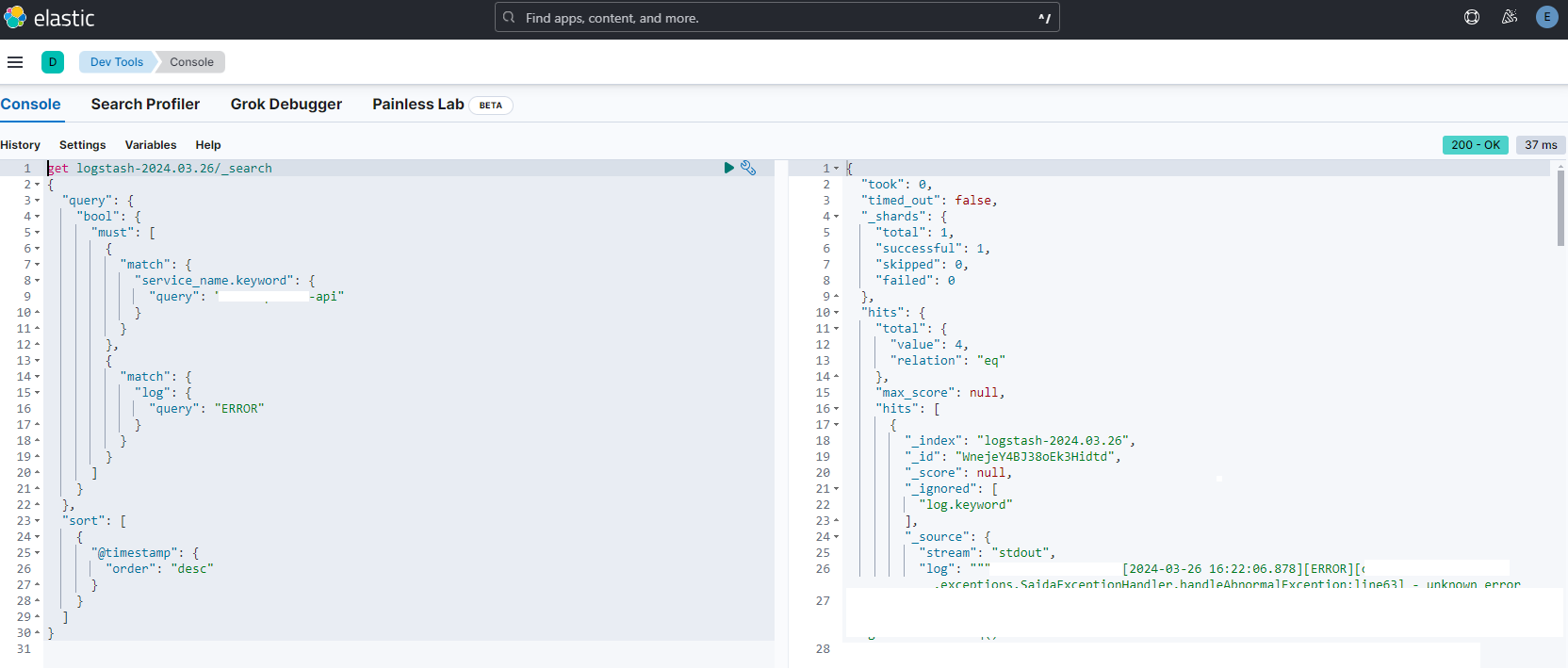
그리고 Kibana의 Devtools 메뉴의 console에서
아래와 같이 해당 서비스의 "ERROR" 로그만 쳐볼 수도 있다.
아, 그리고 쿠버네티스에 떠있는 서비스가 여러 개라서
service_name을 추출하는 부분이 있는데
logback 파일의 appender 부분을 아래와 같이 설정했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true">
<springProperty scope="context" name="logLevel" source="logging.level.root" defaultValue="INFO"/>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[my-service-api][%d{yyyy-MM-dd HH:mm:ss.SSS}][%-5level][%logger.%method:line%line] - %msg%n</pattern>
</encoder>
</appender>
<jmxConfigurator/>
.....생략
</configuration>
|
cs |
서비스명을 추출하고 패턴을 맞추기 위해 삽질을 했다던
fluentd-configmap.yaml 파일의 <parse> 부분과
logback 파일의 appender pattenr 부분과 연관 지어 생각해야 한다.
|
1
2
3
4
5
6
|
<parse>
@type multiline
format_firstline /^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}\.\d+Z stdout F \[[^\]]+\]\[\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d+\]/
format1 /^(?<time>[^\s]+) (?<stream>\S+) F (?<log>.+)$/
</parse>
|
cs |
'Programming > 프로그래밍 내용 정리' 카테고리의 다른 글
| 대규모 트래픽 티켓팅 시스템 설계를 해보다. (0) | 2025.01.08 |
|---|---|
| AWS Lightsail로 HTTPS 서버를 구축해보다. (1) | 2024.09.17 |
| [쿠버네티스] cronjob.yaml - error converting YAML to JSON 에러 해결하기 (0) | 2024.02.29 |
| [Linux] top과 jstat -gc 명령어로 서버와 GC 살펴보기(with 챗지피티) (0) | 2023.06.21 |
| [AWS] VPC / 서브넷 / 인터넷 게이트웨이 / 라우팅 테이블 / 로드밸런싱 (0) | 2023.02.03 |


