스프링배치의 Step 단계에서 데이터를 처리하는 방법은 2가지가 있다.
1. Chunk를 사용한 Step
2. Tasklet을 사용한 Step
이 2가지 방법의 차이점을 아래와 같이 알아보았다.
🎈예제 상황
100개의 문자열을 list로 만들고, list 사이즈를 로그로 찍는 Task
1. Chunk를 사용한 Step
<-- 코드 일부 -->
@Bean
public Step chunkBaseStep() {
return stepBuilderFactory.get("chunkBaseStep")
.<String, String>chunk(10)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build();
}
private ItemReader<String> itemReader() {
return new ListItemReader<>(getItems());
}
private ItemProcessor<String, String> itemProcessor() {
return item -> item + ", Spring Batch";
}
private ItemWriter<String> itemWriter() {
return items -> log.info("chunk item size : {}", items.size());
}
- chunkSize 설정을 통해, 배치 대상을 일정 크기로 쪼개어 반복해서 처리할 수 있음

- Chunk를 사용한 덩어리 기반 처리
- 청크란 작업할 데이터의 각 커밋 사이에 처리되는 row의 수를 의미한다.
- 즉 Chunk 지향 처리란 한번에 읽어오는 Chunk라는 덩어리를 만든 뒤,
- Chunk 단위로 트랜잭션을 다루는 것
- 대량 처리를 하는 경우, Tasklet 보다 비교적 쉽게 구현 가능
- 예를 들어 10,000개의 데이터를 1,000개씩 10개의 덩어리로 수행
- 이를 Tasklet으로 처리하면 10,000개를 한 번에 처리하거나, 수동으로 1,000개씩 분할
- 청크란 작업할 데이터의 각 커밋 사이에 처리되는 row의 수를 의미한다.
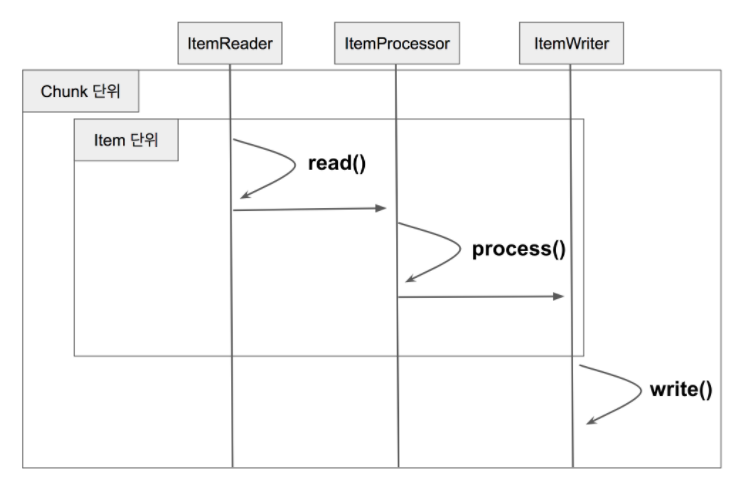
- Reader에서 데이터를 읽어온다.
- 읽어온 데이터를 Processor에서 가공한다.
- 가공된 데이터들은 별도에 공간에 모은 뒤, Chunk 단위만큼 쌓이면 Writer에 전달하고 Writer는 일괄 저장을 시킨다.
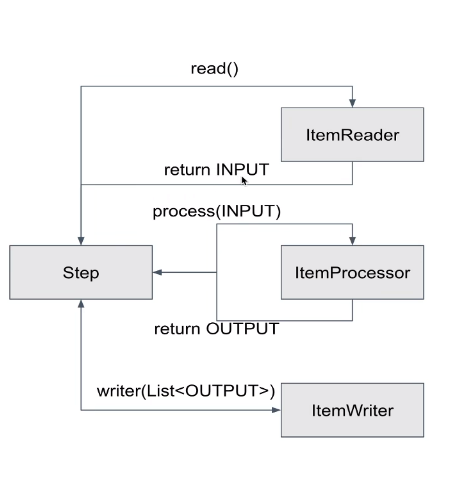

<INPUT, OUTPUT>chunk(int)
- reader에서 INPUT을 reaturn
- processor에서 INPUT을 받아 processing 후, OUTPUT을 return
- writer에서 List<OUTPUT>을 받아 write
2. Tasklet을 사용한 Step
<-- 코드 일부 -->
@Bean
public Step taskBaseStep() {
return stepBuilderFactory.get("taskBaseStep")
.tasklet(this.tasklet())
.build();
}
private Tasklet tasklet() {
return (stepContribution, chunkContext) -> {
List<String> itmes = getItems();
log.info("task item size : {}", itmes.size());
return RepeatStatus.FINISHED;
};
}
private List<String> getItems() {
List<String> items = new ArrayList<>();
for (int i = 0; i < 100; i++) {
items.add(i + "Hello");
}
return items;
}

- Tasklet을 사용한 Task 기반처리
- 데이터 처리과정이 tasklet안에서 한번에 이뤄진다.
- 배치 처리 과정이 비교적 쉬운 경우 쉽게 사용한다.
- 대량 처리를 하는 경우 더 복잡하다.
- 하나의 큰 덩어리를 여러 덩어리로 나누어 처리하기 부적합하다.
전체 코드
package com.ot.schedule.Taskletandchunk;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.support.ListItemReader;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.List;
@Configuration // Spring Batch의 모든 Job은 @Configuration으로 등록해서 사용
@Slf4j
public class ChunkProcessingConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
public ChunkProcessingConfiguration(JobBuilderFactory jobBuilderFactory,
StepBuilderFactory stepBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public Job chunkProcessingJob() {
// JobBuilder를 생성할 수 있는 get() 메서드를 포함. get()메서드는 새로운 JobBuilder를 생성해서 반환.
return jobBuilderFactory.get("chunkProcessingJob")
.incrementer(new RunIdIncrementer()) // run.id 라는 임의의 파라미터를 추가로 사용해 매번 run.id 값을 변경, 매 실행마다 run.id가 변경되니 재실행
.start(this.taskBaseStep())
.start(this.chunkBaseStep())
.build();
}
// =============================== task base step ===============================
@Bean
public Step taskBaseStep() {
return stepBuilderFactory.get("taskBaseStep")
.tasklet(this.tasklet())
.build();
}
private Tasklet tasklet() {
return (stepContribution, chunkContext) -> {
List<String> itmes = getItems();
log.info("task item size : {}", itmes.size());
return RepeatStatus.FINISHED;
};
}
private List<String> getItems() {
List<String> items = new ArrayList<>();
for (int i = 0; i < 100; i++) {
items.add(i + "Hello");
}
return items;
}
// =============================== chunk base step ===============================
@Bean
public Step chunkBaseStep() {
return stepBuilderFactory.get("chunkBaseStep")
.<String, String>chunk(10)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build();
}
private ItemReader<String> itemReader() {
return new ListItemReader<>(getItems());
}
private ItemProcessor<String, String> itemProcessor() {
return item -> item + ", Spring Batch"; // item : ItemReader 읽어온 item
}
private ItemWriter<String> itemWriter() {
// return items -> log.info("chunk item size : {}", items.size());
return items -> items.forEach(log::info);
}
}'Programming > Java & Spring 관련 내용 정리' 카테고리의 다른 글
| [Spring Batch] 오류가 나면 어떻게 해야할까? - Skip과 Retry (0) | 2022.10.28 |
|---|---|
| [Spring Batch] 스프링 배치를 써야 할까? (0) | 2022.09.22 |
| [Spring Batch] 로그인한지 1년 지난 회원 -> 휴면회원으로 상태변경하는 배치구현 (0) | 2022.09.22 |
| [Spring] Filter와 Interceptor의 차이가 무엇인가요? (+ AOP) (0) | 2022.08.15 |
| [Spring] @Transactional이 내부적으로 어떻게 동작하나요? (0) | 2022.08.14 |



